Let’s talk about the strategy design pattern today. According to good old wikipedia, the strategy pattern “defines a family of algorithms, encapsulates each algorithm, and makes the algorithms interchangeable within that family.” In other words, if you have an object most of its behaviour stays the same but there’s one piece that changes, you want to be able to change that one piece without messing with the rest of the object.
A concrete example would probably help :) Let’s say you’re working on a videogame with monsters that attack the player and you want your monsters to be more aggressive at night and less aggressive during the day. The rest of the monster code like movement and tracking health points or inventory stays the same, it’s just one part of the behaviour that you want to be able to change on the fly. The strategy pattern would let you swap in different “should I attack the player?” algorithms any time and the monster code wouldn’t have to change, it would just call a method on the strategy object it was given.
So how would you implement the strategy pattern? Pretty much the same way you’d implement the bridge pattern, actually. The bridge pattern is about organizing your code and the strategy pattern is about how it behaves (thank you stackoverflow), but the way you arrange your interfaces and objects that inherit from them is largely the same. One difference is that your context class (the one that uses the strategy for something) doesn’t have to change – you could have only one of those and still want to use the strategy pattern. Comparing the class diagrams for the two patterns helps show how similar they are.
Here’s a class diagram for the strategy pattern:
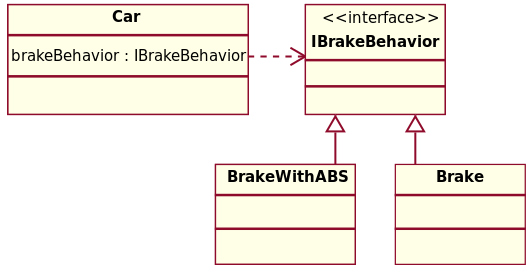
and here’s one for the bridge pattern to compare it to:
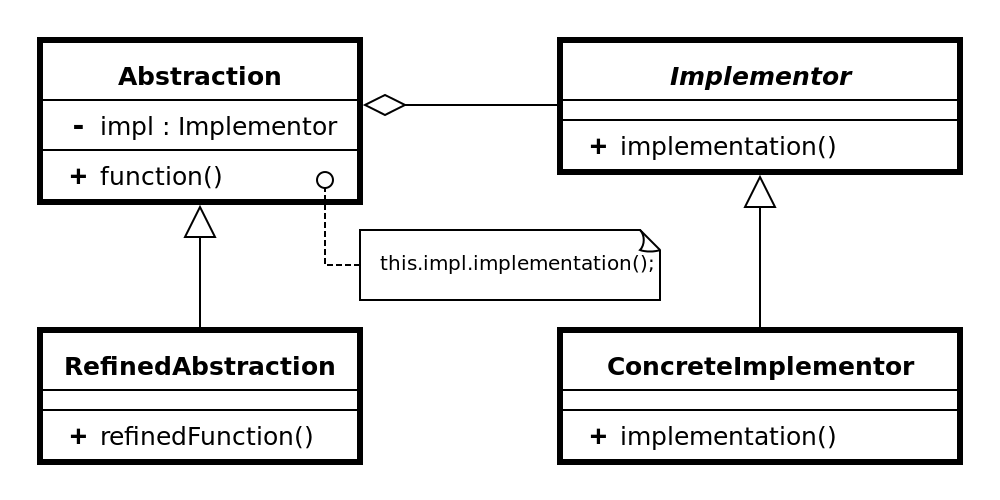
If you imagine there’s another ConcreteImplementor, the bridge pattern looks a lot like the strategy pattern. On it’s own I don’t find the bridge pattern diagram super helpful, but in comparison with the strategy pattern diagram it does help illustrate that there are more things that vary in the bridge pattern than in the strategy pattern.
Given that the patterns are so similar, why do we need both of them? Earlier I mentioned that the bridge pattern is about organizing your code and the strategy pattern is about how it behaves. That might sound like a minor difference, but misunderstandings are a huge, huge problem when you’re developing software. It really does help to make it as clear as you can when you’re talking about how you want to arrange your code and when you’re talking about how you want it to behave.



